深度学习
本文最后更新于:2024年6月21日 凌晨
流程
- 数据处理
- 读入数据
- 划分数据集
- 生成批次数据
- 训练样本集乱序
- 校验数据有效性
- 模型设计
- 网络结构
- 损失函数
- 训练配置
- 优化算法
- 随机梯度下降(SGD):随机梯度下降算法,每次训练少量数据,抽样偏差导致参数收敛过程中震荡。
- 动量(Momentum):引入物理“动量”的概念,累积速度,减少震荡,使参数更新的方向更稳定。
- AdaGrad: 根据不同参数距离最优解的远近,动态调整学习率。学习率逐渐下降,依据各参数变化大小调整学习率。
- Adam: 由于动量和自适应学习率两个优化思路是正交的,因此可以将两个思路结合起来,这就是当前广泛应用的算法。
- 设置学习率
- 优化算法
pycharm
conda环境
新建环境
conda create -n yourEnv python=3.10- –name:也可以缩写为 【-n】,【yourEnv】是新创建的虚拟环境的名字,创建完,可以装anaconda的目录下找到envs/yourEnv 目录
- python=2.7:是python的版本号。也可以指定为【python=3.6】,若未指定,默认为是装anaconda时python的版本.
激活环境
activate yourEnvwindows用户环境变量中添加(改成自己的路径):
D:\Anaconda3
D:\Anaconda3\Scripts
D:\Anaconda3\Library\bin
查看活跃的环境
conda info --envs输出中带有【*】号的的就是当前所处的环境
当==创建环境==时,出现**NoWritablePkgsDirError: No writeable pkgs directories configured.**报错
conda config --add pkgs_dirs D:\Environment\Anaconda3\pkgs
conda config --add envs_dirs D:\Environment\Anaconda3\envsconda其他命令
conda list: 看这个环境下安装的包和版本
conda install numpy scikit-learn: 安装numpy sklearn包
conda env remove -n yourEnv: 删除你的环境
conda env list: 查看所有的环境常见报错
img.imshow(xxx)不显示图片
在pycharm中设置图片不在pycharm中显示(关闭 Show plots in tool window)

import pylab
pylab.show()当控制台报
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.使用
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'动手学深度学习
下载教材
幻灯片版
https://github.com/d2l-ai/d2l-zh-pytorch-slides.git
git clone https://github.com/d2l-ai/d2l-zh-pytorch-slides.git名词解释
有监督学习
无监督学习
线性回归与逻辑回归
- 线性回归是一种用于预测和拟合函数的方法。它用于回归任务,例如用来拟合一条直线。
应用:线性回归常用于连续变量的预测,例如房价预测、股票价格预测等。它可以用来拟合一条直线,描述自变量和因变量之间的关系。
- 逻辑回归是一种用于分类和预测函数的方法。它用于分类任务,可以进行二分类或多分类。它是在给定自变量和超参数后,得到因变量的期望,基于这个期望来处理预测分类问题。
应用:逻辑回归常用于分类问题,例如垃圾邮件分类、疾病诊断等。它可以用来预测一个事件发生的概率,并根据这个概率进行分类。
支持向量机SVM
线性可分支持向量机
$w=(w_1,w_2\cdots w_n)$
$x=(x_1,x_2\cdots x_n)$
b = -10
$w ×x+b=0$
线性支持向量机
非线性支持向量机
Softmax 回归
区别

均方损失

Softmax和交叉熵损失
- 交叉熵常用来衡量两个概率的区别

总结:
- Softmax回归是一个多分类模型
- 使用Softmax操作子得到每个类的预测置信度
- 使用交叉熵来衡量预测和标号的区别作为损失函数
从零开始实现
$softmax(X){ij}=\frac{exp(X{ij})}{∑kexp(X{ik})}$
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition # 应用广播机制实现结果

损失函数
L2 Loss(均方损失)
$l(y,y’)=\frac{1}{2}(y-y’)^2$
L1 Loss
$l(y,y’)=|y-y’|$
图像分类数据集
import torch
from torch.utils import data
from d2l import torch as d2l
def get_dataloader_workers():
"""使用4个进程来读取数据。"""
return 4
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers())
timer = d2l.Timer()
for X, y in train_iter:
continue
# 打印读取数据时间
print(f'{timer.stop():.2f} sec')感知机
二分类问题
给定输入x,权重w,和偏移b,感知机输出:
$\omicron=\sigma(<w,x>+b)$ $\sigma(x)=\begin{cases} 1,if \quad x>0 \ -1, otherwise \end{cases}$
二分类:-1或1
- Vs.回归输出实数
- Vs.Softmax回归输出概率

收敛定理
- 数据在半径r内
- 余量$\rho$分类两类
- y($x^T$w+b) $\geqslant$ $\rho$
对于$||W||^2+b^2\leqslant1$
- 感知机保证在$\frac {r^2+1}{\rho^2}$步后收敛
XOR问题
感知机不能拟合XOR函数,它只能产生线性分割面
多层感知机

X,Y先进入蓝色进行判断:(1,3)为+,(2,4)为-
X,Y再进入黄色进行判断:(1,2)为+,(3,4)为-
product对前面的结果做乘积,相同为+ ,相异为-
总结
- 多层感知器使用隐藏层和激活函数来得到非线性模型
- 常用激活函数是sigmoid,Tanh,ReLU
- 使用softmax来处理多类分类
- 超参数为隐藏层数,和各个隐藏层大小
代码
import torch
from torch import nn
from d2l import torch as d2l
import pylab
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
# 批量大小
batch_size = 64
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 超参数
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X @ W1 + b1)
return (H @ W2 + b2)
loss = nn.CrossEntropyLoss()
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
d2l.predict_ch3(net, test_iter)
pylab.show()结果

模型选择
训练误差:模型在训练数据上的误差
泛化误差:模型在新数据上的误差
验证数据集:评估模型好坏的数据集(不要和测试数据集混在一起)
测试数据集:只使用一次(例如竞赛排行榜的数据集,只使用一次)
K-折交叉验证
将含有N 个样本的数据集,分成K 份,每份含有 $\frac{N}{K}$个样本。选择其中一份作为验证集,另外K − 1份作为训练集,验证集集就有K种情况。
- 在没有足够多数据时使用
- 使用i块作为验证数据集,其余作为训练集
最后K个验证集误差求平均
- 常用:K = 5 或 10(程序跑5次或10次)
总结
- 训练数据集:训练模型参数
- 验证数据集:选择模型超参数
- 非大数据集上通常使用K-折交叉验证
过拟合和欠拟合

| $\frac{数据}{模型容量}$ | 简单 | 复杂 |
|---|---|---|
| 低 | 正常 | 欠拟合 |
| 高 | 过拟合 | 正常 |
模型容量的影响

数据复杂度
- 样本个数
- 每个样本的元素个数
- 时间、空间结构
- 多样性
总结
- 模型容量需要匹配数据复杂度,否则可能导致欠拟合和过拟合
- 统计机器学习提供数学工具来衡量模型复杂度
- 实际中一般靠观察训练误差和验证误差
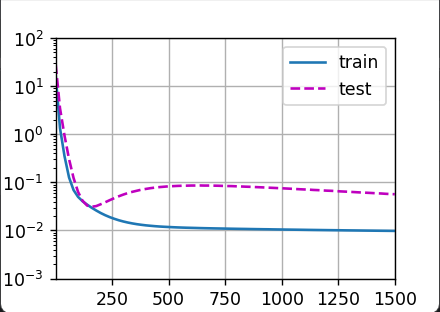
结果
正常

欠拟合

过拟合
卷积神经网络
语言识别
pip install SpeechRecognition