Jarvis助手
本文最后更新于:2024年6月21日 凌晨
ChatGPT
使用Azure的Azure OpenAI服务,可以选择openai库或者使用API的方式
python调用openai库
导入库并列出模型
import openai
import os
import re
import requests
import sys
from num2words import num2words
import os
import pandas as pd
import numpy as np
from openai.embeddings_utils import get_embedding, cosine_similarity
import tiktoken
API_KEY = os.getenv("AZURE_OPENAI_API_KEY")
RESOURCE_ENDPOINT = os.getenv("AZURE_OPENAI_ENDPOINT")
openai.api_type = "azure"
openai.api_key = API_KEY
openai.api_base = RESOURCE_ENDPOINT
openai.api_version = "2023-05-15"
url = openai.api_base + "/openai/deployments?api-version=2023-05-15"
r = requests.get(url, headers={"api-key": API_KEY})
print(r.text)封装成类,新建chat.py
import os
import openai
import tiktoken
class Chat_service:
prompt = ""
template = """
person: {}
AI:"""
def __init__(self):
# OpenAI API
openai.api_type = "azure"
openai.api_key = API_KEY
openai.api_base = RESOURCE_ENDPOINT
openai.api_version = "2023-05-15"
def num_tokens_from_string(self, string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
def receive(self, question, choose=0):
filedir = os.path.dirname(os.path.realpath(__file__))
list = {0: '/prompts/prompts.txt',
1: '/prompts/开发者模式.txt',
2: '/prompts/派蒙.txt',
3: '/prompts/深度学习.txt',
4: '/prompts/文字探险.txt'
}
# 加入提示词
file_url = filedir + list[choose]
if os.path.exists(file_url):
with open(file_url, "r", encoding='utf-8') as f:
self.prompt = f.read()
prompt_local = self.prompt + self.template.format(question)
result = openai.Completion.create(
engine="text-davinci-003", # “text-davinci-003” 模型用于文本生成,“code-davinci-002”模型用于代码生成
prompt=prompt_local,
temperature=0.9,
max_tokens=1000, # 4097是openai的限制,
stop=["person", "AI", "\n"],
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=-0.6
)
text = result.choices[0]['text']
return text
if __name__ == '__main__':
cs = Chat_service()
n = int(input("请输入模式(0:默认、1:开发者模式、2:派蒙、3:深度学习、4:文字探险):"))
while True:
q = input("Person:")
if q == '退出':
break
print(cs.receive(q, n))字节流返回
(stream=True)
import openai
openai.api_type = "azure"
openai.api_base = {终结点}
openai.api_version = "2023-05-15"
openai.api_key = {密钥}
template = """
person: {什么是resnet18}
AI:"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=template,
temperature=0.9,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
best_of=1,
stream=True,
stop=["Human:", "AI:"])
collected_events = []
completion_text = ''
# iterate through the stream of events
for event in response:
collected_events.append(event) # save the event response
event_text = event['choices'][0]['text'] # extract the text
completion_text += event_text # append the text
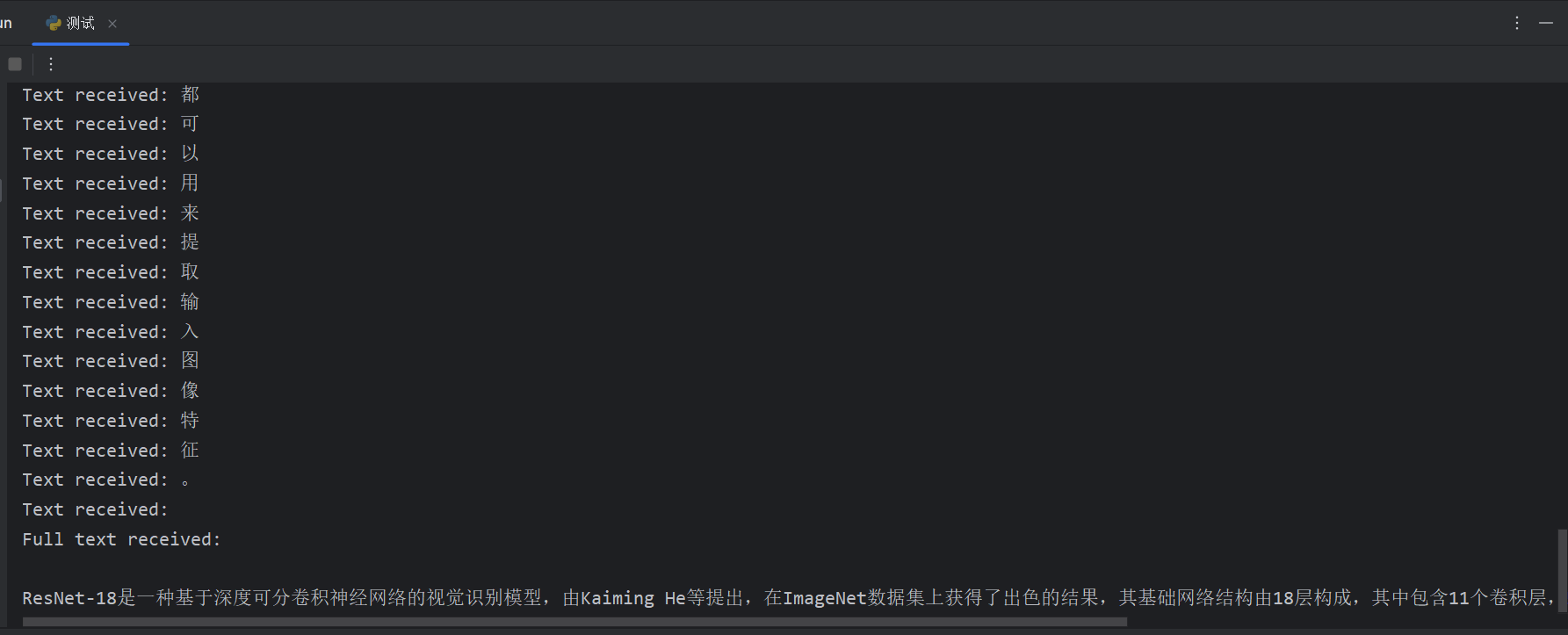
print(f"Text received: {event_text}")
print(f"Full text received: {completion_text}")结果演示:
xxxxxxxxxx Object massage = redisUtil.lGetIndex(“sensor”, 0);JSONObject jsonObject = JSON.parseObject(massage.toString());String sn = jsonObject.getString(“SN”);BigDecimal temp = jsonObject.getBigDecimal(“Temp”);BigDecimal humidity = jsonObject.getBigDecimal(“Humidity”);String time = jsonObject.getString(“time”);java
也可以使用openai的密钥,在腾讯云上创建云函数,挂载到美国,可直连接口。:arrow_down:
云函数
app.py
from flask import Flask,request
opeailoaded="0"
try:
import openai
openai.api_key = 'sk-Oq8KpkA9mNTOwJvINVFrT3BlbkFJ64FAZ7MfFDJE01jc'
opeailoaded="1"
except Exception as e:
opeailoaded="0"
app = Flask(__name__)
@app.route('/')
def hello_world():
if opeailoaded=="1":
return 'opeailoaded'
else:
return "openai not loaded"
@app.route('/ask')
def ask():
try:
query=request.args.get("query")
response=openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": query}
]
)
return response ['choices'][0]['message']['content']
except Exception as e:
print(str(e))
return "无法获取结果"
if __name__ == '__main__':
app.run(host='0.0.0.0',port=9000)
点击查看-终端
输入安装 openai 库
cd src # 进入源代码库
pip3 install openai -t. # 安装到源代码路径下点击部署
加入语音服务
使用Azure的认知语音服务,可文字转语音,语音转文字,也可以选择不同的声音。
封装成类,新建voice_service.py
import azure.cognitiveservices.speech as speechsdk
import keyboard
import time
class VoiceService:
text = ''
def __init__(self):
speech_key = {密钥}
service_region = {新建服务时的地区}
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region)
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
speech_config.speech_synthesis_language = "zh-CN"
speech_config.speech_synthesis_voice_name ="zh-CN-XiaoyanNeural" # 女:zh-CN-XiaomoNeural 男:zh-CN-XiaoyanNeural
self.speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region)
self.speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, language="zh-CN")
def speak_text(self, text):
self.text = text
if text != '':
self.speech_synthesizer.speak_text_async(text).get()
else:
self.speech_synthesizer.speak_text_async('我好像出错了,你能再说一遍吗?').get()
def speak(self, text):
self.speak_text(text)
def listen(self):
print("按下空格键开始监听")
keyboard.wait('space') # 等待空格键按下
result = self.speech_recognizer.recognize_once_async().get()
return result.text
def listen_and_speak(self):
text = self.listen()
print(f'问: {text}')
if '再见' in text:
text = '再见,祝您生活愉快'
self.speak_text(text)
return False
else:
self.speak_text(text)
print(f'答: {text}')
return True语音交互
首先将上面两个类保存下来,导入。
import re
from chat import Chat_service
from voice_service import VoiceService
vs = VoiceService()
cs = Chat_service()
n = 0
def text_chat(n):
print('有什么需要我帮助的吗?')
while True:
try:
q = input('问:')
if q == '退出':
break
response = cs.receive(q, n)
print('AI:' + response)
response = re.sub(r'\(.*?\)', '', response)
vs.speak(response)
except Exception as e:
print(e)
def voice_chat(n):
print('我是一个智能机器人,我可以回答你的问题。')
vs.speak('有什么需要我帮助的吗?')
while True:
try:
q = vs.listen()
if q in '退出':
break
response = cs.receive(q, n)
print('AI:' + response)
response = re.sub(r'\(.*?\)', '', response)
vs.speak(response)
except Exception as e:
print(e)
if __name__ == '__main__':
choose = int(input('选择模式(1.文字聊天,2.语音聊天):'))
n = int(input('选择模式(0.默认,1.开发者模式,2.派蒙,3.深度学习,4.文字探险):'))
if choose == 1:
text_chat(n)
else:
voice_chat(n)人脸识别
本文内容
1.使用基于Haar特征的Cascade级联分类器进行人脸识别(听起来好高大上,但其实原理很简单)
2.用人脸识别同样的道理,扩展到人眼识别上
3.用opencv自带的Harr级联分类器进行人脸、人眼与微笑识别
什么是Harr特征
Haar特征包含三种:边缘特征、线性特征、中心特征和对角线特征。每种分类器都从图片中提取出对应的特征。
什么是Cascade级联分类器
基于Haar特征的cascade级联分类器是Paul Viola和 Michael Jone在2001年的论文”Rapid Object Detection using a Boosted Cascade of Simple Features”中提出的一种有效的物体检测方法。
Cascade级联分类器的训练方法:Adaboost
级联分类器的函数是通过大量带人脸和不带人脸的图片通过机器学习得到的。对于人脸识别来说,需要几万个特征,通过机器学习找出人脸分类效果最好、错误率最小的特征。训练开始时,所有训练集中的图片具有相同的权重,对于被分类错误的图片,提升权重,重新计算出新的错误率和新的权重。直到错误率或迭代次数达到要求。这种方法叫做Adaboost。
在Opencv中可以直接调用级联分类器函数。
将弱分类器聚合成强分类器
最终的分类器是这些弱分类器的加权和。之所以称之为弱分类器是因为每个分类器不能单独分类图片,但是将他们聚集起来就形成了强分类器。论文表明,只需要200个特征的分类器在检测中的精确度达到了95%。最终的分类器大约有6000个特征。(将超过160000个特征减小到6000个,这是非常大的进步了) 。
级联的含义:需过五关斩六将才能被提取出来
事实上,一张图片绝大部分的区域都不是人脸。如果对一张图片的每个角落都提取6000个特征,将会浪费巨量的计算资源。
如果能找到一个简单的方法能够检测某个窗口是不是人脸区域,如果该窗口不是人脸区域,那么就只看一眼便直接跳过,也就不用进行后续处理了,这样就能集中精力判别那些可能是人脸的区域。 为此,有人引入了Cascade 分类器。它不是将6000个特征都用在一个窗口,而是将特征分为不同的阶段,然后一个阶段一个阶段的应用这些特征(通常情况下,前几个阶段只有很少量的特征)。如果窗口在第一个阶段就检测失败了,那么就直接舍弃它,无需考虑剩下的特征。如果检测通过,则考虑第二阶段的特征并继续处理。如果所有阶段的都通过了,那么这个窗口就是人脸区域。 作者的检测器将6000+的特征分为了38个阶段,前五个阶段分别有1,10,25,25,50个特征(前文图中提到的识别眼睛和鼻梁的两个特征实际上是Adaboost中得到的最好的两个特征)。根据作者所述,平均每个子窗口只需要使用6000+个特征中的10个左右。
OpenCV中的Haar-cascade检测
OpenCV 既可以作为检测器也可以进行机器学习训练。如果你打算训练自己的分类器识别任意的物品,比如车,飞机,咖啡杯等。你可以用OpenCV 创造一个。完整的细节在:Cascade Classifier Training中。
# 人脸识别
# 导入opencv-python
import cv2
# 读入一张图片,引号里为图片的路径,需要你自己手动设置
img = cv2.imread('image1.jpg',1)
# 导入人脸级联分类器引擎,'.xml'文件里包含训练出来的人脸特征
face_engine = cv2.CascadeClassifier(cv2.data.haarcascades+'haarcascade_frontalface_default.xml')
# 用人脸级联分类器引擎进行人脸识别,返回的faces为人脸坐标列表,1.3是放大比例,5是重复识别次数
faces = face_engine.detectMultiScale(img,scaleFactor=1.3,minNeighbors=5)
# 对每一张脸,进行如下操作
for (x,y,w,h) in faces:
# 画出人脸框,蓝色(BGR色彩体系),画笔宽度为2
img = cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
# 在"img2"窗口中展示效果图
cv2.imshow('img2',img)
# 监听键盘上任何按键,如有按键即退出并关闭窗口,并将图片保存为output.jpg
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.imwrite('output.jpg',img)
对单个图片识别
# 单张图片人脸+眼睛识别
#导入opencv
import cv2
# 导入人脸级联分类器引擎,'.xml'文件里包含训练出来的人脸特征,cv2.data.haarcascades即为存放所有级联分类器模型文件的目录
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades+'haarcascade_frontalface_default.xml')
# 导入人眼级联分类器引擎吗,'.xml'文件里包含训练出来的人眼特征
eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades+'haarcascade_eye.xml')
# 读入一张图片,引号里为图片的路径,需要你自己手动设置
img = cv2.imread('image3.png')
# 用人脸级联分类器引擎进行人脸识别,返回的faces为人脸坐标列表,1.3是放大比例,5是重复识别次数
faces = face_cascade.detectMultiScale(img, 1.3, 5)
# 对每一张脸,进行如下操作
for (x,y,w,h) in faces:
# 画出人脸框,蓝色(BGR色彩体系),画笔宽度为2
img = cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
# 框选出人脸区域,在人脸区域而不是全图中进行人眼检测,节省计算资源
face_area = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(face_area)
# 用人眼级联分类器引擎在人脸区域进行人眼识别,返回的eyes为眼睛坐标列表
for (ex,ey,ew,eh) in eyes:
#画出人眼框,绿色,画笔宽度为1
cv2.rectangle(face_area,(ex,ey),(ex+ew,ey+eh),(0,255,0),1)
# 在"img2"窗口中展示效果图
cv2.imshow('img2',img)
# 监听键盘上任何按键,如有案件即退出并关闭窗口,并将图片保存为output.jpg
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.imwrite('output.jpg',img)
调用电脑摄像头识别
# 调用电脑摄像头进行实时人脸+眼睛识别
import cv2
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades+'haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades+'haarcascade_eye.xml')
# 调用摄像头摄像头
cap = cv2.VideoCapture(0)
while(True):
# 获取摄像头拍摄到的画面
ret, frame = cap.read()
faces = face_cascade.detectMultiScale(frame, 1.3, 5)
img = frame
for (x,y,w,h) in faces:
# 画出人脸框,蓝色,画笔宽度微
img = cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
# 框选出人脸区域,在人脸区域而不是全图中进行人眼检测,节省计算资源
face_area = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(face_area)
# 用人眼级联分类器引擎在人脸区域进行人眼识别,返回的eyes为眼睛坐标列表
for (ex,ey,ew,eh) in eyes:
#画出人眼框,绿色,画笔宽度为1
cv2.rectangle(face_area,(ex,ey),(ex+ew,ey+eh),(0,255,0),1)
# 实时展示效果画面
cv2.imshow('frame2',img)
# 每5毫秒监听一次键盘动作
if cv2.waitKey(5) & 0xFF == ord('q'):
break
# 最后,关闭所有窗口
cap.release()
cv2.destroyAllWindows()摄像头实时微笑识别
# 调用电脑摄像头进行实时人脸+眼睛+微笑识别
import cv2
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades+'haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades+'haarcascade_eye.xml')
smile_cascade = cv2.CascadeClassifier(cv2.data.haarcascades+'haarcascade_smile.xml')
# 调用摄像头摄像头
cap = cv2.VideoCapture(0)
while(True):
# 获取摄像头拍摄到的画面
ret, frame = cap.read()
faces = face_cascade.detectMultiScale(frame, 1.3, 2)
img = frame
for (x,y,w,h) in faces:
# 画出人脸框,蓝色,画笔宽度微
img = cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
# 框选出人脸区域,在人脸区域而不是全图中进行人眼检测,节省计算资源
face_area = img[y:y+h, x:x+w]
## 人眼检测
# 用人眼级联分类器引擎在人脸区域进行人眼识别,返回的eyes为眼睛坐标列表
eyes = eye_cascade.detectMultiScale(face_area,1.3,10)
for (ex,ey,ew,eh) in eyes:
#画出人眼框,绿色,画笔宽度为1
cv2.rectangle(face_area,(ex,ey),(ex+ew,ey+eh),(0,255,0),1)
## 微笑检测
# 用微笑级联分类器引擎在人脸区域进行人眼识别,返回的eyes为眼睛坐标列表
smiles = smile_cascade.detectMultiScale(face_area,scaleFactor= 1.16,minNeighbors=65,minSize=(25, 25),flags=cv2.CASCADE_SCALE_IMAGE)
for (ex,ey,ew,eh) in smiles:
#画出微笑框,红色(BGR色彩体系),画笔宽度为1
cv2.rectangle(face_area,(ex,ey),(ex+ew,ey+eh),(0,0,255),1)
cv2.putText(img,'Smile',(x,y-7), 3, 1.2, (0, 0, 255), 2, cv2.LINE_AA)
# 实时展示效果画面
cv2.imshow('frame2',img)
# 每5毫秒监听一次键盘动作
if cv2.waitKey(5) & 0xFF == ord('q'):
break
# 最后,关闭所有窗口
cap.release()
cv2.destroyAllWindows()
局限性
1.仅为人脸检测,非人脸“辩识”,即只能框出人脸的位置,看不出人脸是谁。
2.仅能标出静态图片和视频帧上的人脸、人眼和微笑,不能进行“活体识别”,即不能看出这张脸是真人还是手机上的照片,如果用于人脸打卡签到、人脸支付的话会带来潜在的安全风险。
3.仅为普通的机器学习方法,没有用到深度学习和深层神经网络。